5.3. Active learning object segmentation witloof plantjes
Toepassen Maskal voor de detectie van witloof plantjes in het veld
Voor de detectie van de palloxen in vorig hoofstuk werd gestart van een dataset van 40 beelden die reeds allemaal manueel gelabeld waren door middel van polygonen. De waarde van Active learning in een kleine dataset met grote objecten is beperkt.
Deze problemen werden wel opgemerkt in de dataset met witloof plantjes op het veld. Deze plantjes zijn klein, er staan er veel op elke foto en er zijn een 100 tot 1000 foto’s. De foto’s hadden een afmeting van 4128/3096 wanneer de foto’s gelabeld worden op een beeldscherm met resolutie 1920/1080 betekent dit dat wanneer je op 100% vergroting wil kijken maar 1/6 van de foto bekijkt.

Originele foto 4128/3090 pixels

100% vergrootte foto op een beeldscherm van 1920/1080
Uit de grote dataset werden een 100 foto’s als subsample genomen om detectie van zaailingen uit te testen.
Deze foto’s zijn nodig om het model te trainen, te testen en te valideren. De Test en Val foto’s moeten vooraf gelabeld worden en er werd gekozen om voor elk 8 foto’s manueel te labelen. Drie categorieën van labels werden gespecifieerd: De witloof zaailingen, onkruid die buiten de plant rijen werd opgemerkt en de zichtbare schoen van de persoon die de foto’s genomen heeft. Onderstaande figuren tonen de verdeling va de 3 categoriën van labels in de Validatie en test dataset

Verdeling van de labels in de validatie dataset

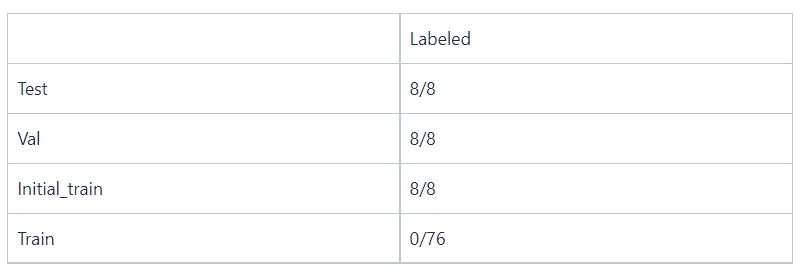
Drie mapjes werden aangemaakt:
- Val met 8 foto’s en 8 json labels
- Test met 8 andere foto’s en 8 json labels
- Train met de resterende niet gelabelde foto’s.
MaskAL werd uigevoerd en 8 foto’s werden voorgesteld om te labellen:
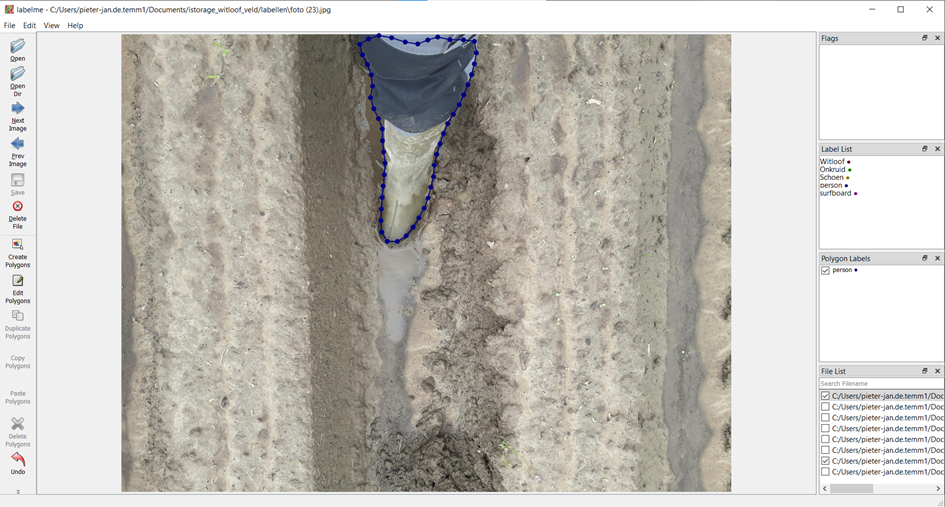
zoals in het Pallox voorbeeld suggereert het COCO model al labels voor de foto’s. Zo wordt het been van de fotograaf al herkend als ‘person’ in deze dataset label ik het been als “Schoen”
Na het labellen van deze 8 foto’s bekomen we volgende verdeling van de labels in de train dataset

Na het labellen van deze 8 foto’s bekomen we volgende verdeling van de labels in de train dataset
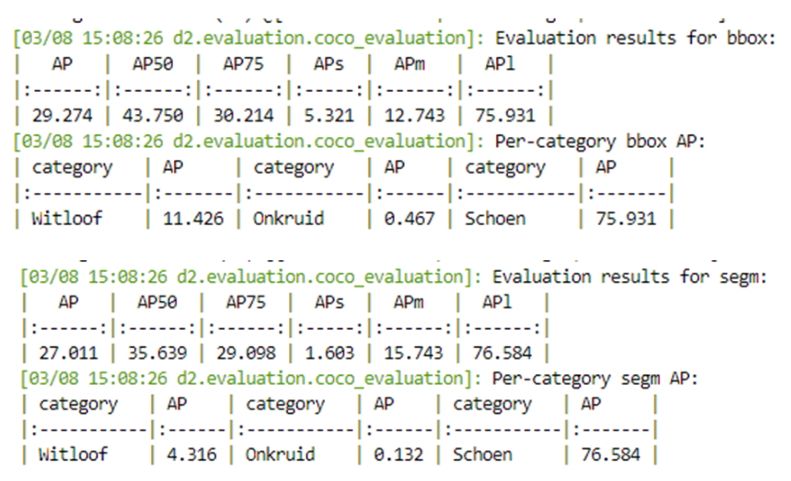
De gemiddelde precisie van de bbox en segmentatie zijn enkel voor de “Schoen categorie hoog, voor Onkruid is het echter heel laag. De doel categorie Witloof behaalt een lage gemiddelde precisie.
Finaal wordt het model ook getest op de Test dataset.
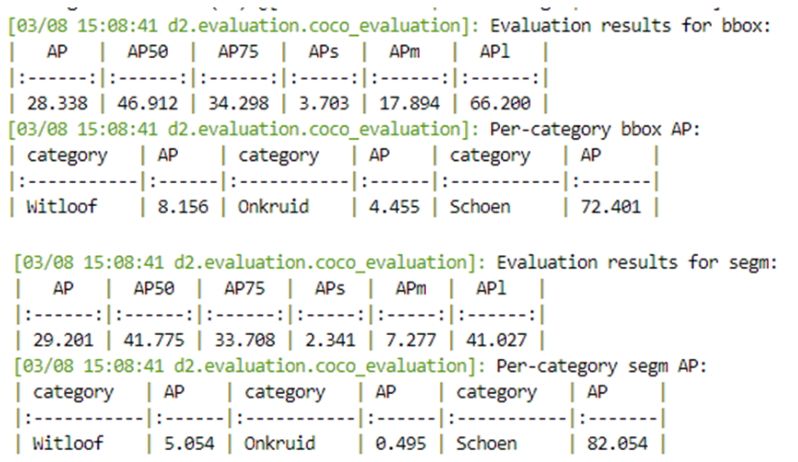
De resultaten op de test dataset liggen in lijn met de resultaten van de validatie dataset,.
Een klein probleem is wanneer na het labellen er een fout optreedt in het trainen. Dan moet het proces herstart worden. Maar wanneer MaskAL herstart wordt, dan stelt hij andere foto’s voor om te labellen.
Wanneer het proces faalt dan zit je in de situatie dat je reeds gelabelde foto’s hebt.
In deze situatie kan je direct het model starten van de foto’s. Dan moet een nieuw mapje “initial_train” aangemaakt worden waar de gelabelde foto’s in zitten en “use_initial_train_dir” moet op True gezet worden.
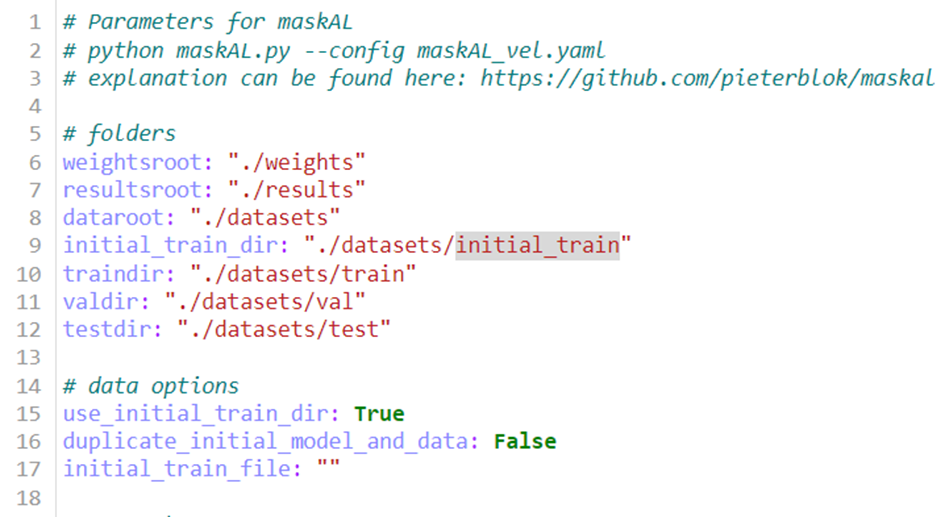
Er moet dus een nieuw mapje “initial_train” gemaakt worden in de datasets folder. De verdeling van de foto’s over de mapjes is dan de volgende:
Na het trainen op de 8 foto’s stelt Maskal volgende 3 gelabelde beelden voor met labels voor “Witloof”,”Onkruid” en “Schoen”.

Foto1: automatisch gelabeled door MaskAL detecteerd de rijen witloof plantjes en een schoen

Foto2: automatisch gelabeled door MaskAL detecteerd de rijen witloof plantjes, een onkruid dat buiten de rijen valt en een schoen

Foto3: automatisch gelabeled door MaskAL detecteerd de rijen witloof plantjes, foutief gedetecteerde witloof plantjes buiten de rijen en een schoen.
Deze foto’s tonen aan dat manueel labelen van 24/100 foto’s en een model trainen, valideren en testen reeds een groot deel van de plantjes in nieuwe foto’s detecteert. In labelme kan in Foto3 bijvoorbeeld de labels van de onruid plantjes buiten de witloof rijen aangepast worden van “witloof” naar “Onkruid”. Witloof plantjes die het model gemist zou hebben kunnen nog manueel toegevoegd worden.
Door Toepassen van Active leaning kan het labellen van de foto’s gereduceerd worden van gemiddeld 30 polygonen per foto naar een 5-tal herlabelen en manueel labelen. De focus van het manueel labelen verschuift in active learning ook naar de objecten die het model nog niet goed kan herkennen gezien de objecten die het model reeds goed kan herkennen reeds automatisch gelabeld worden.